GB300 與 VR200(Vera Rubin NVL72)平台性能比較及物料成本分析
本文將詳細解說摩根士丹利研究報告中的Exhibit 3物料清單(Bill of Materials,簡稱BOM)。本文已完整整合各項組件佔比數據,包括GB300與VR200的成本佔總額百分比、成本差異以及佔比變化,同時新增GB300與VR200的市場定位分析。逐步說明技術細節、成本結構與商業意義。
一、NVIDIA NVL72機架簡介
NVIDIA NVL72是一種「機架規模」的AI超級電腦系統,放置在資料中心的標準機櫃(rack)內。一個機架整合72顆高性能GPU、36顆CPU,以及高速互聯、記憶體、電源與冷卻等基礎設施,能夠獨立處理大規模人工智慧訓練、推理或新一代代理式AI(Agentic AI)任務。其設計目標是協助雲端服務商或大型企業建構高效能AI資料中心(俗稱AI工廠),大幅提升運算密度與整體效率。
- GB300:目前世代的Blackwell Ultra平台,已進入量產出貨階段,是2025年的主流AI硬體。
- VR200:下一代Vera Rubin平台,預計2026年推出,採用全新Rubin GPU與Vera CPU,代表NVIDIA技術的重大躍進。
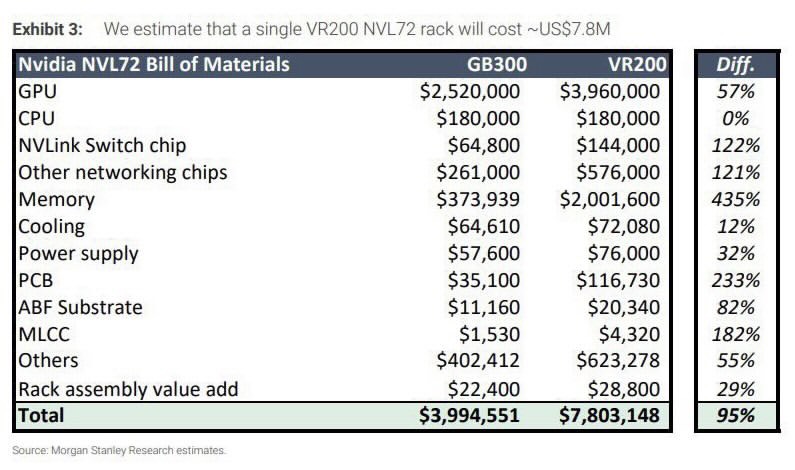
根據摩根士丹利估計,單一GB300 NVL72機架的物料總成本約399萬美元,VR200則上升至約780萬美元,整體增幅95%。以下整合提供的精確數據,清楚呈現各項組件的成本與佔比變化。
二、各項組件成本、佔比及變化詳細比較
以下直接使用提供的精確數據(單位:美元,佔比為四捨五入後的百分比),並標註成本差異與佔比變化:
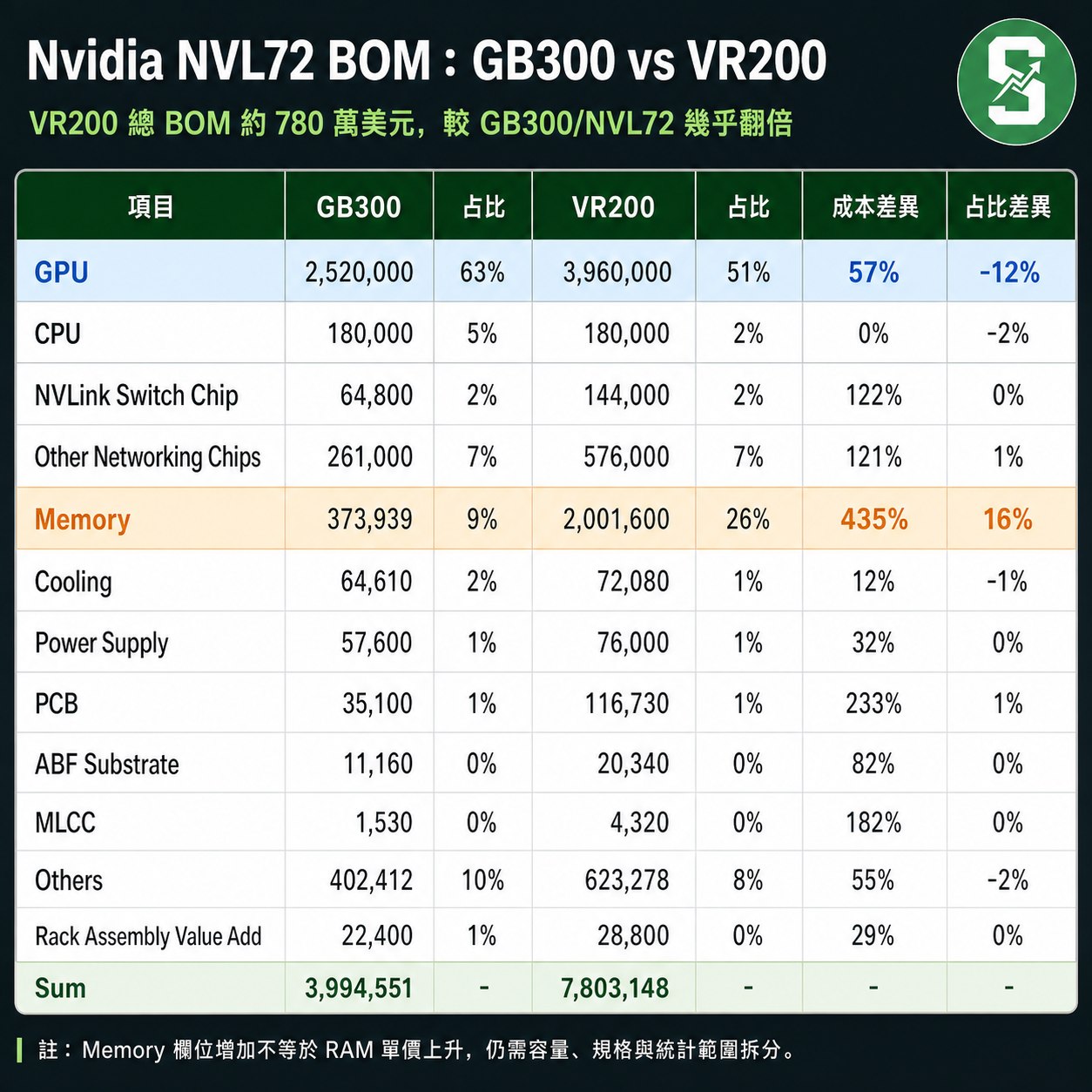
關鍵觀察:在GB300中,GPU主導高達63%的成本,是絕對核心;到了VR200,GPU佔比下降至51%(減少12個百分點),而Memory(記憶體)佔比則從9%暴增至26%(增加16個百分點),成為第二大成本項目。這清楚顯示新一代平台在記憶體與互聯技術上的投資大幅增加,整體成本結構更趨多元與平衡。
三、GB300 與 VR200 的市場定位:皆為旗艦機型,主要應用於訓練與推理
是的,GB300 NVL72與VR200 NVL72皆為NVIDIA的旗艦機型。它們是NVIDIA目前與下一代最高階的「機架規模AI超級電腦平台」,專為大型AI資料中心(AI工廠)設計,被業界視為AI基礎設施的頂級解決方案。兩者均採用液冷設計、完整NVLink互聯,將72顆GPU與36顆CPU視為「單一大腦」般運作,是建構 hyperscaler(超大型雲端業者)AI叢集的核心產品。
在應用面上,兩者皆同時支援大規模訓練(training)與高效能推理(inference),並非僅專注其中一項:
- 訓練(Training):適用於訓練數兆參數的基礎模型(Foundation Models)、混合專家模型(MoE)與多模態AI。GB300已用於Microsoft與OpenAI等客戶訓練多兆參數模型;VR200更進一步,能以原本1/4的GPU數量完成相同訓練工作,大幅降低時間與能源消耗。
- 推理(Inference):特別強調AI推理與「代理式AI」(Agentic AI),包括長上下文處理、即時回應、多步驟推理等新一代應用。GB300專為「test-time scaling inference」(推理時動態增加運算以提升準確度)與AI推理任務優化;VR200則在推理上表現更突出,NVIDIA官方表示其每百萬token成本較Blackwell降低約90%(即1/10費用),特別適合高度互動的深度推理任務。
總結而言,這兩款旗艦機型是NVIDIA推動AI從「訓練階段」全面進入「推理與實時應用階段」的關鍵利器,幫助客戶在相同預算下處理更多AI工作負載,加速商業化部署。
四、VR200性能是否優於GB300
是的,VR200在多個關鍵指標上大幅領先GB300。以下以新手易懂方式說明(數據以單一NVL72機架為基準):
-
運算能力(FLOPS,每秒浮點運算次數)
VR200在FP4低精度任務上,推理性能可達約3.6 exaFLOPS,較GB300提升約3.3至5倍;在訓練任務中,每顆GPU性能提升約3.5倍。這代表VR200能用更少的GPU完成相同AI模型訓練,顯著縮短時間並節省能源。 -
記憶體頻寬(Memory Bandwidth)
VR200每顆GPU配備288 GB HBM4高頻寬記憶體,頻寬高達22 TB/s,較GB300提升約2.8倍,讓AI模型處理資料更有效率。 -
互聯技術(NVLink)
VR200採用新一代NVLink 6,機架總頻寬達260 TB/s,較GB300提升約2倍,確保系統如單一大腦般運作。 -
整體效率與商業效益
NVIDIA表示,VR200在AI推理任務的每百萬token成本較GB300降低約90%(只需1/10費用)。這讓企業在相同預算下能處理更多AI工作,長期投資報酬率(ROI)更高,尤其適合雲端服務商如Microsoft、Google、Amazon等大型客戶加速AI商業化部署。
總結性能優勢:VR200不僅運算速度更快,更透過更高密度、頻寬與互聯,實現「性能躍升同時效率提升」,幫助NVIDIA客戶以更低營運成本建構強大AI基礎設施。
五、BOM成本上升的真正原因:規格與數量升級
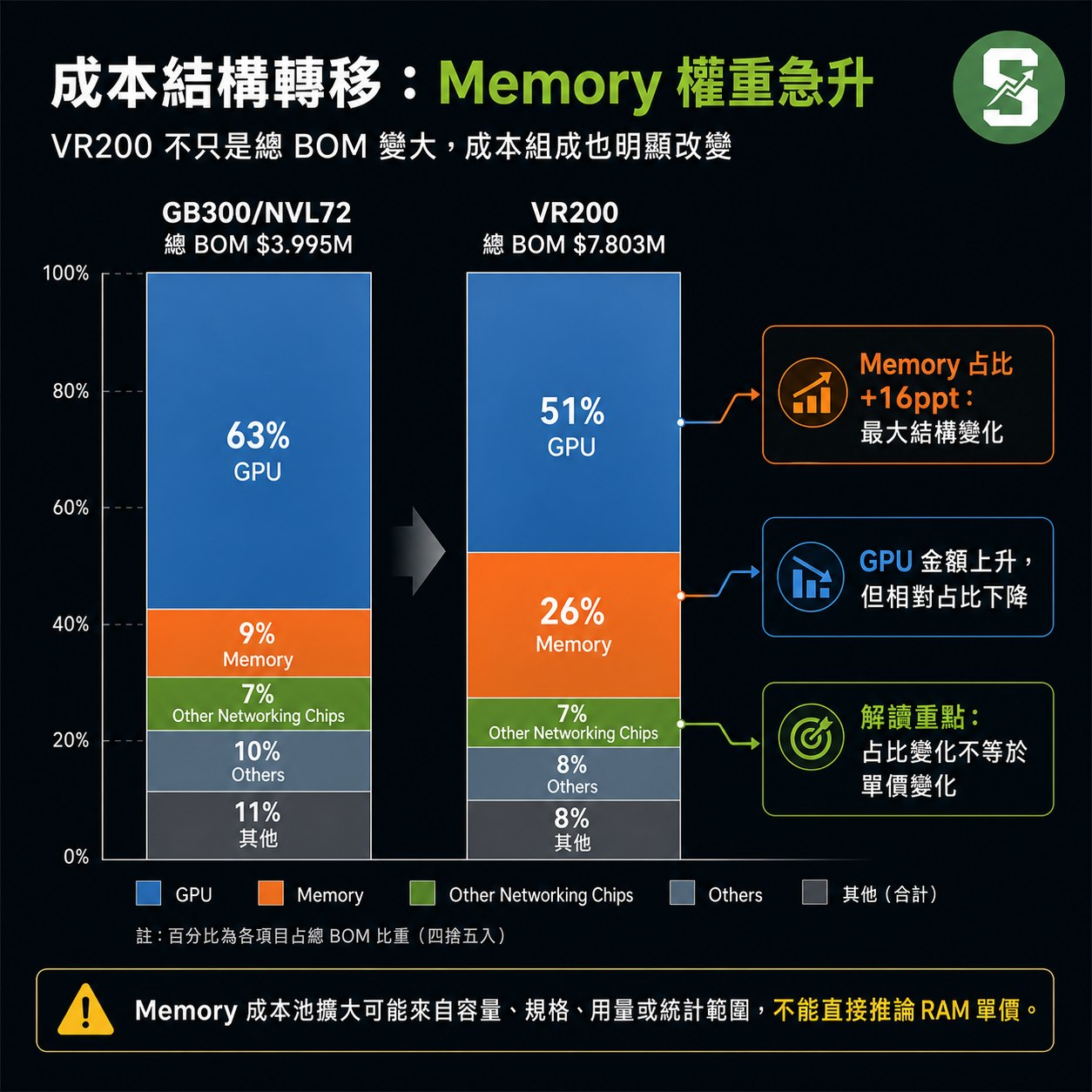
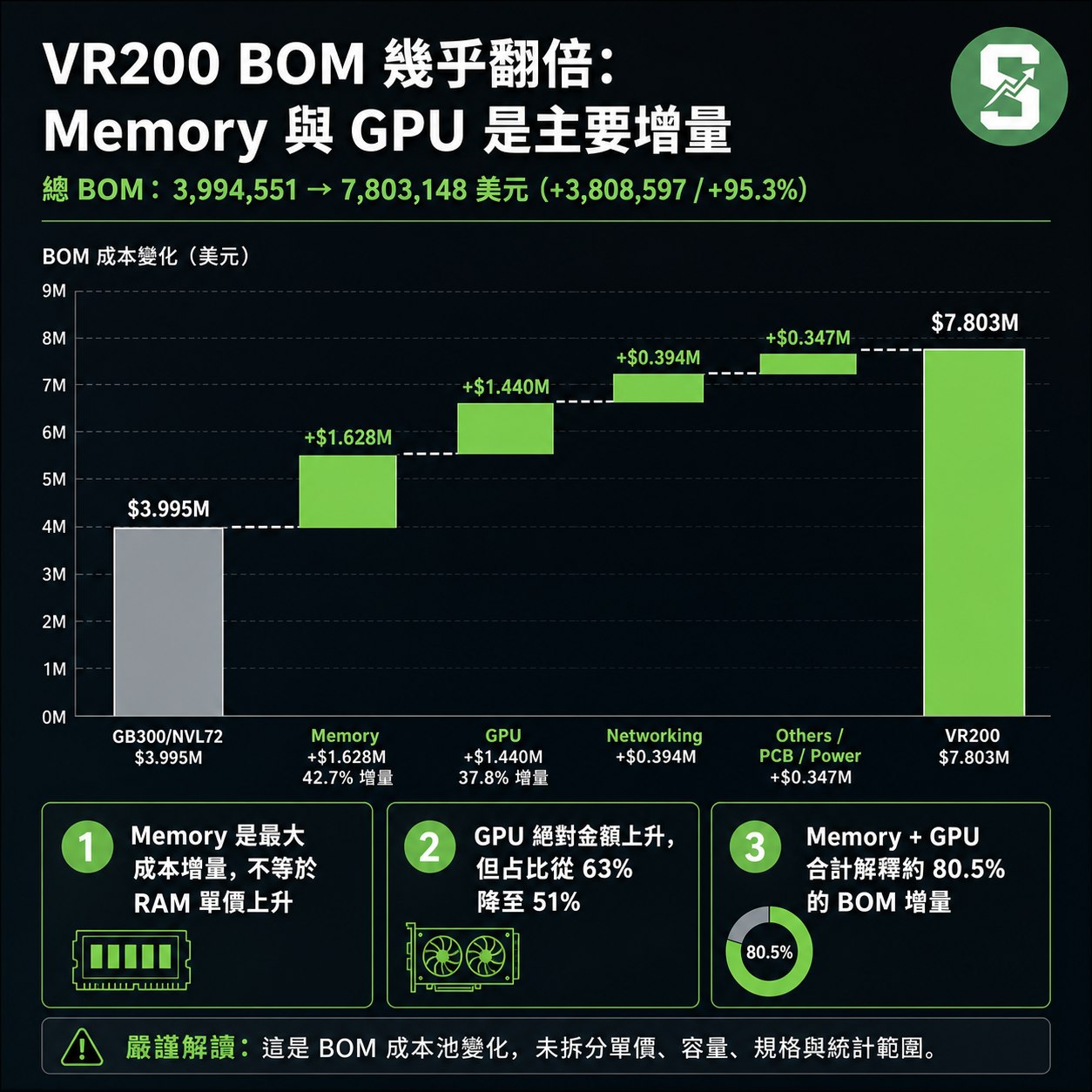
記憶體成本從373,939美元升至2,001,600美元(+435%),佔比從9%跳升至26%(+16個百分點),主要不是單純漲價,而是因為VR200使用了更多且更先進的記憶體:每顆Rubin GPU搭載更高頻寬的HBM4記憶體,每顆Vera CPU配備高達1.5 TB LPDDR5X系統記憶體,36顆CPU總計54 TB,遠高於GB300配置。
其他項目漲幅同樣反映規格升級:
- NVLink Switch Chip與Other networking Chips(+122%與+121%):新一代晶片支援更高頻寬與更低延遲,佔比維持穩定或微增。
- PCB(+233%)、冷卻、電源供應等:因GPU功耗更高,需要更強大的支援系統,佔比雖小但絕對金額明顯上升。
VR200總成本幾乎翻倍,正是NVIDIA技術進步的必然結果——短期資本支出(CapEx)增加,但長期每單位AI運算成本下降。
六、從這張圖表得出的商業與產業洞見
- 成本結構轉變:GPU主導地位下降(-12%),記憶體重要性大幅提升(+16%),顯示HBM4供應鏈將成為AI產業關鍵瓶頸,對記憶體廠商(如SK Hynix、美光)帶來重大成長機會。
- 對NVIDIA:透過完整系統設計(從GPU到互聯、記憶體),強化其在AI生態系的領導地位與技術溢價。作為旗艦平台供應商,NVIDIA能掌控AI工廠的核心建置需求。
- 對資料中心業者與雲端巨頭:雖然初始投資更高,但性能與效率提升帶來更好投資報酬率,加速AI基礎設施部署。
- 對供應鏈:網路晶片、電源、冷卻與先進封裝廠商將受惠於訂單成長,整體AI市場2026年後的基礎設施投資規模將進一步擴大,推動人工智慧從實驗室走向廣泛商業應用。

免責聲明: 本文內容僅供一般研究參考、教育用途與歷史案例討論,用於整理公司資料、業務變化或市場脈絡,不構成任何形式的投資建議、招攬、買賣訊號或個人化交易指示。Stock Fundamentals Lab 並非證監會持牌機構,文中不提供目標價、入市時機或買賣建議。股市有風險,請自行審慎評估並按需要諮詢持牌專業顧問。